기계 인식을 위한 데이터셋
5-flowers 데이터셋 사용
- 데이지, 민들레, 장미, 해바라기 ,튤립
- 각각 꽃 이름으로 라벨링
이미지 데이터 읽기
def read_and_decode(filename, reshape_dims):
# 파일 읽기
img = tf.io.read_file(filename)
# 압축된 문자열을 3D uint8 텐서로 변환
img = tf.image.decode_jpeg(img, channels=IMG_CHANNELS)
# [0,1] 범위의 float로 변환
img = tf.image.convert_image_dtype(img, tf.float32)
# 원하는 크기로 조정
return tf.image.resize(img, reshape_dims)
컬러이미지는 일반적으로 channels=3, grayscale 이미지라면 channels=1이 됨
#그레이스케일
img = tf.image.decode_jpeg(img, channels=1)
이미지 데이터를 시각화
# 파일 한 개를 읽고 표시해 봄
def show_image(filename):
img = read_and_decode(filename, [IMG_HEIGHT, IMG_WIDTH])
plt.imshow((img.numpy()));
show_image(
"gs://practical-ml-vision-book/flowers_5_jpeg/flower_photos/daisy/754296579_30a9ae018c_n.jpg")
[와일드 카드 문자]
* - 유닉스에서는 ‘\’ 등으로 escape하지 않으면 0개 이상의 임의의 문자열과 매칭됨
? - 임의의 1개의 문자 매칭됨
[와일드 카드 매칭]
- 와일드 카드가 포함한 문자열과 일반 문자열 매칭 확인
+ recursive=True로 설정하고 '**'를 사용하면 모든 하위 디렉토리까지 탐색
file_path = glob.glob('dir/**', recursive=True)
glob() 함수
.glob.glob ( glob 모듈의 glob 함수)
사용자가 제시한 조건에 맞는 파일명을 리스트 형식으로 반환
데이터셋 파일 읽기
tf.strings.regex_replace()
basename = tf.strings.regex_replace(filename, "gs://cloud-ml-data/img/flower_photos/", "")- filename 에 "gs://cloud-ml-data/img/flower_photos/"가 존재한다면 "" 로 변경
tf.data.TextLineDataset()
텍스트 파일에서 텍스트를 로드하고 파일의 각 행이 데이터 세트의 요소가 되는 데이터 세트를 생성
CLASS_NAMES = [item.numpy().decode("utf-8") for item in
tf.strings.regex_replace(
tf.io.gfile.glob("gs://practical-ml-vision-book/flowers_5_jpeg/flower_photos/*"),
"gs://practical-ml-vision-book/flowers_5_jpeg/flower_photos/", "")]
def decode_csv(csv_row):
record_defaults = ["path", "flower"]
filename, label_string = tf.io.decode_csv(csv_row, record_defaults)
img = read_and_decode(filename, [IMG_HEIGHT, IMG_WIDTH])
# label = tf.math.equal(CLASS_NAMES, label_string)
return img, label_string
record_defaults
각 필드의 디폴트 값을 지정해주는 것은 물론, 각 필드의 데이터 타입(string, int, float 등)을 정의해줌
record_defaults = ["path", "flower"]첫번째 필드는 string 형이고, 디폴트 값은 "path"
두번째 필드도 string 형이고, 디폴트 값은 "flower"
for img, label in dataset.take(3):
avg = tf.math.reduce_mean(img, axis=[0, 1]) # 이미지의 평균 픽셀
print("label =",label)
print("avg =", avg)
axis=[0,1]
avg=tf.math.reduce_mean(img, axis=[0,1])이미지의 세로(높이) 및 가로(너비) 축을 기준으로 평균이 계산됨
▶ 이미지의 각 채널에 대해 평균이 계산
케라스를 사용한 선형 모델
가중 평균 -> 가중치에 변형을 가함
가중 합 - 복수의 데이터를 단순히 합하는 것이 아니라 각각의 수에 어떤 가중치 값을 곱한 후 이 곱셈 결과들을 다시 합한 것
케라스 모델
tf.keras.Sequential()는 여러 층을 순서대로 쌓아서 신경망 모델을 구성
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS)),
tf.keras.layers.Dense(len(CLASS_NAMES), activation='softmax')
])tf.keras.layers.Dense()는 완전 연결된 하나의 층
tf.keras.layers.Dense(len(CLASS_NAMES))
예측함수
batch_image = tf.reshape(img, [1, IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS])
batch_pred = model.predict(batch_image)
pred = batch_pred[0]

+ 확률, 오즈, 로짓
확률 - 여러 번의 시행 중 특정 사건이 발생할 가능성
오즈 - 사건이 일어날 확률을 사건이 일어나지 않을 확률로 나눈 것 p/(1-p)
로짓 - 사건이 일어날 오즈의 자여 로그
(시그모이드는 로짓의 역함수)

활성화 함수
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS)),
tf.keras.layers.Dense(len(CLASS_NAMES), activation='softmax')softmax 함수 사용 (linear, sigmoid, softmax 등이 존재)\
옵티마이저(최적화기법)
확률적 경사 하강법 (SGD), 모멘텀, AdaGrad, Adam
Ftrl (Follow-the-Regularized-Leader)
- 범주형 특징이 많은 극도로 희소한 데이터셋에서 잘 작동하는 경향이 있는 옵티마이저
- 이전 업데이트에서 얻은 모델의 가중치를 따라감. 어떤 방향으로 가중치가 이동했는지를 고려하여 새로운 업데이트 수행
훈련 데이터셋을 읽을 때 배치로 처리함
train_dataset = (tf.data.TextLineDataset(
"gs://practical-ml-vision-book/flowers_5_jpeg/flower_photos/train_set.csv").
map(decode_csv)).batch(10)
훈련 손실
옵티마이저 - 훈련 데이터셋에서 모델의 오차를 최소화하는 가중치를 선택하려 시도
[원핫인코딩]
- 범주형 데이터
범주형 - 'A', 'B', 'C'와 같이 종류를 표시하는 데이터
[범주형 교차 엔트로피]
- 클래스가 3개 이상인 데이터를 대상으로 사용하는 손실 함수
- 편차가 줄어들 수록 출력 값이 0개 가까워짐
- 각 행의 총 합은 1
▶ CategoricalCrossentropy()와 SparseCategoricalCrossentropy() 차이
CategoricalCrossentropy():
- 레이블(Label)을 원-핫 인코딩(one-hot encoding) 형태로 입력받음
클래스 1에 해당하는 레이블 - [1, 0, 0], 클래스 2에 해당하는 레이블 - [0, 1, 0], 클래스 3에 해당하는 레이블 - [0, 0, 1]
#원핫 인코딩
label = tf.math.eqaul(CLASS_NAMES, label_string)
#손실
tf.keras.losses.CategoricalCrossentropy(from_logits=False)
SparseCategoricalCrossentropy():
- 레이블을 정수 형태로 입력으로 받음 (라벨 다중 분류 문제에는 희소 표현이 부적함함)
클래스 1에 해당하는 레이블 - 1, 클래스 2에 해당하는 레이블 - 2, 클래스 3에 해당하는 레이블- 3
#정수 인덱스
label = tf.argmax(tf.math.eqaul(CLASS_NAMES, label_string))
#손실
tf.keras.losses.CategoricalCrossentropy(from_logits=False)
오차지표

정밀도
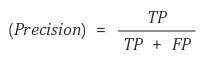
재현율

F1 점수
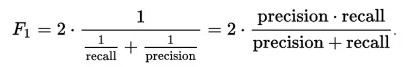
확률 임곗값에 따라 달라지는 정밀도와 재현율의 절충점은 정밀도- 재현율 곡선에 나타냄.
ROC 곡선 아래 면적인 AUC는 성능을 총채적으로 판단하는 척도로 쓰임
- 좌상단에 붙을 수록 성능이 높음
- x축 = 1- 특이도, y축 = 민감도

모델 훈련 실습
훈련 데이터셋 만든 후, decode_csv()로 JPEG 이미지를 읽어 디코딩
<모델 생성 및 보기>
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS)),
tf.keras.layers.Dense(len(CLASS_NAMES), activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])

모델 피팅
training_plot(['loss', 'accuracy'], history);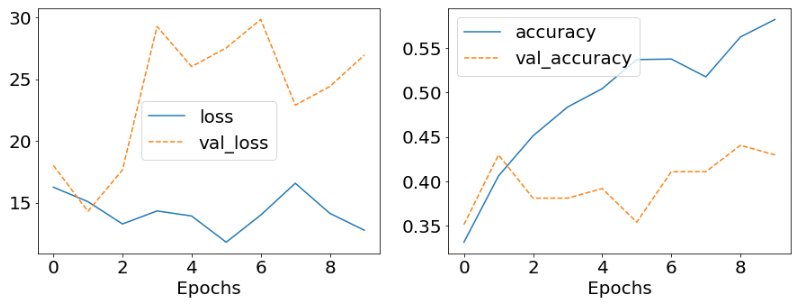
과적합 발생 확인
▶ 이미지 회귀
회귀 문제
- 주어진 데이터포인트 x에 해당하는 실제 값으로 주어지는 타겟 y를 예측하는 과제
ex. 강우량 예측
케라스를 사용한 신경망
더 복잡한 모델을 만들고 싶음
▶ 입력 레이어와 출력 레이어 사이에 Dense 레이어를 두어 더 복잡한 모델을 얻음 = 신경망
은닉층
입력레이어도, 출력 레이어도 아니지만 훈련 가능 가중치를 가짐
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
#은닉층 추가
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(len(CLASS_NAMES), activation='softmax')
])

활성화 함수
시그모이드, tanh, elu
렐루 - 정의역의 절반이 0 이기에 가중치 업데이트가 전혀 일어나지 않는, 죽은 렐루 (dead ReLUs)라는 문제가 나타남.
학습률
학습률이 너무 높으면 옵티마이저가 극솟값들을 지나쳐버릴 수 있음.
학습률이 너무 낮으면 모델이 극솟값을 벗어나지 못함 ▶ 학습률이 낮을 수록 모델이 늦게 수렴
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=..., metrics=...)
규제
L1 규제항, L2 규제항

regularizer = tf.keras.regularizers.l1_l2(0,0.001)
조기 중단
검증 정확도가 더 이상 나아지지 않을 때는 훈련을 멈추는 것이 좋음
▶ model.fit() 함수에 콜백을 전달함.
tuner.search(
train_dataset, validation_data=eval_dataset,
epochs=5,
callbacks=[tf.keras.callbacks.EarlyStopping(patience=1)]
)에폭 수는 patience 파라미터로 설정
하이퍼파라미터 튜닝
def build_model(hp):
lrate = hp.Float('lrate', 1e-4, 1e-1, sampling='log')
l1 = 0
l2 = hp.Choice('l2', values=[0.0, 1e-1, 1e-2, 1e-3, 1e-4])
num_hidden = hp.Int('num_hidden', 32, 256, 32)
regularizer = tf.keras.regularizers.l1_l2(l1, l2)
# 은닉층이 한 개 있는 NN
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS)),
tf.keras.layers.Dense(num_hidden,
kernel_regularizer=regularizer,
activation=tf.keras.activations.relu),
tf.keras.layers.Dense(len(CLASS_NAMES),
kernel_regularizer=regularizer,
activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=lrate),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['accuracy'])
return model
학습률 (lrate) - 1e-4 ~ 1e-1 사이의 부동소수점 값
L2 규제 값 - 미리 정의된 다섯 개 중에서 선택
숨은 노드의 수(num_hidden) - 32~256 사이의 정수로 32씩 증가)
▶ 케라스 튜너(Keras Tuner) 최적화 알고리즘
- Keras와 TensorFlow를 기반으로 한 하이퍼파라미터 튜닝 라이브러리
하이퍼파라미터 튜닝방법으로는 Bayesian Optimization, Grid Search, Random Search, Hyperband 등이 사용됨.
▶ 베이지안 최적화 (Bayesian Optimization)
- 미지의 함수가 반환하는 값의 최소 또는 최댓값을 만드는 최적해를 짧은 반복을 통해 찾아내는 최적화 방식
tuner = kt.BayesianOptimization(
build_model,
objective=kt.Objective('val_accuracy', 'max'),
max_trials=10,
num_initial_points=2,
overwrite=False) # 새로 시작하려면 True
tuner.search() 로 탐색 실행
실행이 끝나면 topN 을 시행하여 최종 검증 정확도가 가장 높은 것들을 얻음.
topN = 2
for x in range(topN):
print(tuner.get_best_hyperparameters(topN)[x].values)
print(tuner.get_best_models(topN)[x].summary())심층 신경망
- 은닉층이 2 이상인 신경망
layers = [tf.keras.layers.Flatten(
input_shape=(IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS),
name='input_pixels')]
layers = layers + [
tf.keras.layers.Dense(nodes,
kernel_regularizer=regularizer,
activation=tf.keras.activations.relu,
name='hidden_dense_{}'.format(hno))
for hno, nodes in enumerate(num_hidden)
]
layers = layers + [
tf.keras.layers.Dense(len(CLASS_NAMES),
kernel_regularizer=regularizer,
activation='softmax',
name='flower_prob')
]
model = tf.keras.Sequential(layers, name='flower_classification')
DNN 성능을 높이는 방법
- 드롭아웃 레이어와 배치 정규화
1. 드롭아웃
훈련을 거듭할 때마다 드롭아웃 레이어가 p 의 확률로 네트워크로부터 뉴런을 무작위로 제거함
탈락한 뉴런에서 나온 결과는 손실 계산에 넣지 않고, 가중치도 갱신하지 않음
tf.keras.layers.Dropout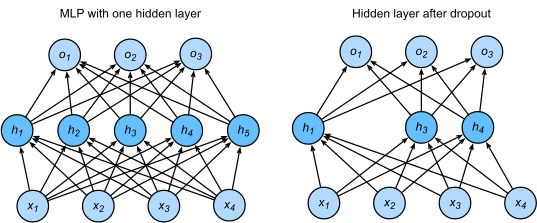
2. 배치 정규화
평균을 빼고 표준편차로 나눔으로써 데이터의 훈련 배치에서 뉴런 출력을 정규화함
뉴런당 2개의 학습 가능 파라미터 (scale, center)를 도입하고, 이 값을 사용해 뉴럽의 입력 데이터를 정규화함
tf.keras.layers.BatchNormalization(scale=False, center=True)

활성화를 Dense에서 빼내 배치 정규화 이후 별도 레이어로 옮김
'AI' 카테고리의 다른 글
| [OpenCV 오류] module 'cv2' has no attribute 'createThinPlateSplineShapeTransformer' (0) | 2024.01.30 |
|---|---|
| [머신러닝 프로젝트] LOL 경기 예측 (5) | 2023.12.16 |
| Yolov5, Yolov8 공부 (1) | 2023.05.30 |
| Faster R-CNN (0) | 2023.05.30 |
| Teachable Machine을 사용한 쓰러짐 감지 AI 구현 (0) | 2023.01.05 |


