1. 프로젝트 동기
이번 롤드컵에서 한국팀 'T1'이 우승하였고 게임을 진행하는 동안 수많은 감독과 코치진, 다양한 전략이 필요하다는 것을 알게 되었음.
경기에 대한 여러 분석 영상을 보다가 'lol'게임과 관련한 데이터셋을 다뤄보고 싶다고 생각함.
게임 중 여러 특징들을 가지고 블루 팀의 '평균 레벨 값'을 예측하는 회귀 모델과, 블루 팀의 '승패'를 예측하는 분류 모델을 만들어보고자 함.
2. 데이터셋 소개
LOL: League of Legends Diamond Ranked Games (10 min)
https://www.kaggle.com/datasets/bobbyscience/league-of-legends-diamond-ranked-games-10-min
League of Legends Diamond Ranked Games (10 min)
Classify LoL ranked games outcome by looking at the first 10min worth of data
www.kaggle.com
데이터셋 내용:
- 10015개의 각 Game 정보 (Solo로 진행)
- 레벨 : DIAMOND I ~ MASTER, 서로 비슷한 게임 실력을 가지고 있다고 가정
- 게임 초반 10분의 경기 정보를 담고 있음


0번째 정보 : 각 game의 고유한 id
1~20번째 정보 : Blue팀에 관한 정보
21~39번째 정보 : Red팀에 관한 정보
| 0 gameId 1 blueWins 2 blueWardsPlaced 3 blueWardsDestroyed 4 blueFirstBlood 5 blueKills 6 blueDeaths 7 blueAssists 8 blueEliteMonsters 9 blueDragons 10 blueHeralds 11 blueTowersDestroyed 12 blueTotalGold 13 blueAvgLevel 14 blueTotalExperience 15 blueTotalMinionsKilled 16 blueTotalJungleMinionsKilled 17 blueGoldDiff 18 blueExperienceDiff 19 blueCSPerMin 20 blueGoldPerMin |
21 redWardsPlaced 22 redWardsDestroyed 23 redFirstBlood 24 redKills 25 redDeaths 26 redAssists 27 redEliteMonsters 28 redDragons 29 redHeralds 30 redTowersDestroyed 31 redTotalGold 32 redAvgLevel 33 redTotalExperience 34 redTotalMinionsKilled 35 redTotalJungleMinionsKilled 36 redGoldDiff 37 redExperienceDiff 38 redCSPerMin 39 redGoldPerMin |
특징 중 생소한 단어들은 LoL 게임 중에 사용되는 아이템 이름임

3. 회귀 (Regression)
목적 : 블루팀의 평균 레벨 [13] blueAvgLevel 예측
[데이터 전처리]
블루팀의 정보만을 사용할 것이므로 Red team의 정보 [21]~[39] drop 시킴.
Gold에 관한 정보가 blueTotalGold, blueGoldDiff, blueGoldPerMin으로 3가지가 있으므로 중복을 피하기 위해 [12] blueTotalGold 만을 사용함
+ blueAvgLevel = blueTotalExperience와 동일하게 볼 수 있음
▷ blueTotalExperience Drop 시킴
data.drop(data.columns[[0] + [14] + [17] + [20] + list(range(21, 40))], inplace=True, axis=1)

데이터셋을 Train, Test로 나누었음.
X, y을 7:3 비율로 나눔.
y = 'blueAvgLevel'
X = data.drop('blueAvgLevel', axis=1).values
y = data['blueAvgLevel'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
[RandomForrestRegressor을 이용해 특징 중요도 산출]

blueTotalExperience가 과도하게 높은 중요도를 보임. ▶ 문제점
※ Blue팀의 평균 레벨 = blueTotalExperience와 동일하게 볼 수 있음. (결국 Total 경험치 값으로 레벨이 정해지기 때문에)
blueTotalExperience로 진행했던 그래프들을 blueExperienceDiff로 변경 + blueTotalExperience Drop 진행
blueExperienceDiff = 레드팀과의 경험치 획득량 차이

[Heatmap을 사용한 Correlation 분석]
cm = np.corrcoef(data[cols].values.T)
hm = heatmap(cm, row_names=cols, column_names=cols, figsize=(20, 18))
plt.show()
[Scatterplot Matrix]
cols = [
'blueWins',
'blueWardsPlaced',
'blueWardsDestroyed',
'blueFirstBlood',
'blueKills',
'blueDeaths',
'blueAssists',
'blueEliteMonsters',
'blueDragons',
'blueHeralds',
'blueTowersDestroyed',
'blueTotalGold',
'blueAvgLevel',
'blueTotalExperience',
'blueTotalMinionsKilled',
'blueTotalJungleMinionsKilled',
'blueExperienceDiff',
'blueCSPerMin'
]
# 여러분의 데이터프레임을 사용하도록 수정
scatterplotmatrix(data[cols].values, figsize=(13, 11),
names=cols, alpha=0.5)
plt.tight_layout()
plt.show()
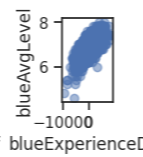
blueAvgLevel과 blueExperienceDiff의 그래프를 확인한 결과 그래프가 이상적으로 나타남을 확인
blueExperienceDiff 값이 클 수록 AvgLevel 값도 커짐
▶blueAvgLevel을 예측하는데에 높은 중요도를 지니고 있음!
[Epoch별 Cost function 그려보기]
X = data[['blueExperienceDiff']].values
y = data['blueAvgLevel'].values
from sklearn.preprocessing import StandardScaler
sc_x = StandardScaler()
sc_y = StandardScaler()
X_std = sc_x.fit_transform(X)
y_std = sc_y.fit_transform(y[:, np.newaxis]).flatten()
lr = LinearRegressionGD()
lr.fit(X_std, y_std)
plt.plot(range(1, lr.n_iter+1), lr.cost_)
plt.ylabel('SSE')
plt.xlabel('Epoch')
plt.tight_layout()
# plt.savefig('images/10_05.png', dpi=300)
plt.show()
※ 에폭이 진행될 수록 그래프가 수렴해야 하는데 발산하는 문제점 발생
모델을 LinearRegressionGD에서 AdagradRegressor로 수정해보았더니 그래프가 정상적으로 수렴함
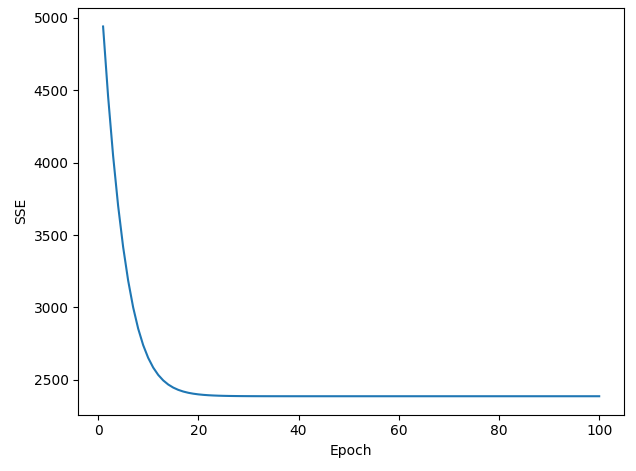
| learning_rate = 0.01 | learning_rate = 0.001 | learning_rate = 0.0001 |
 |
 |
 |
learning_rate를 0.01, 0.001, 0.0001로 수정해서 그래프를 비교해본 결과 lr = 0.001일 때 가장 이상적으로 수렴하는 것을 확인하였음
[AdagradRegressor을 이용해 모델 시각화]
class AdagradRegressor:
def __init__(self, learning_rate=0.01, n_iter=100):
self.learning_rate = learning_rate
self.n_iter = n_iter
self.weights = None
self.cost_ = []
def fit(self, X, y):
self.weights = np.zeros(1 + X.shape[1])
for _ in range(self.n_iter):
output = self.net_input(X)
errors = (y - output)
self.weights[1:] += self.learning_rate / np.sqrt(np.sum(errors**2)) * X.T.dot(errors)
self.weights[0] += self.learning_rate / np.sqrt(np.sum(errors**2)) * errors.sum()
cost = 0.5 * np.sum(errors**2)
self.cost_.append(cost)
return self
def net_input(self, X):
return np.dot(X, self.weights[1:]) + self.weights[0]
def predict(self, X):
return self.net_input(X)
+ 이전에 진행했던 blueTotalExperience에 비하면 성능이 떨어진다는 것을 확인할 수 있음.

또한 blueTotalExperience를 사용했을 때 log와 sqrt을 사용해서 linear regression 그래프를 그려보았지만, blueExperienceDiff 값에는 음수 값도 존재하기 때문에 log 그래프를 사용할 수 없음
[LinearRegression을 사용한 Pipeline]
from sklearn.pipeline import make_pipeline
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
pipe_regressor = make_pipeline(StandardScaler(), PCA(n_components=2),
LinearRegression())
pipe_regressor.fit(X_train, y_train)
y_pred_regressor = pipe_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred_regressor)
print('평균 제곱 오차(MSE): %.3f' % mse)
[LinearRegression을 사용한 Learning Curve]
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=None, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
else:
plt.ylim(0.3, 0.5) # y축 범위를 0에서 1로 설정
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
plt.grid()
plt.plot(train_sizes, train_scores_mean, 'o-', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
# Linear Regression Learning Curve
estimator_lr = make_pipeline(StandardScaler(), PCA(n_components=2), LinearRegression())
plot_learning_curve(estimator_lr, "Linear Regression Learning Curve", X_val, y_val, cv=5)
plt.show()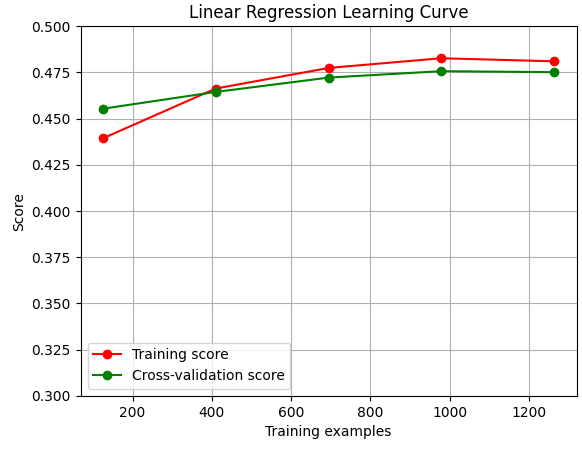
[잔차 그래프 그려보기]
slr = LinearRegression()
slr.fit(X_train, y_train)
y_train_pred = slr.predict(X_train)
y_test_pred = slr.predict(X_test)
plt.scatter(y_train_pred, y_train_pred - y_train,
c='steelblue', marker='o', edgecolor='white',
label='Training data')
plt.scatter(y_test_pred, y_test_pred - y_test,
c='limegreen', marker='s', edgecolor='white',
label='Test data')
plt.xlabel('Predicted values')
plt.ylabel('Residuals')
plt.legend(loc='upper left')
plt.hlines(y=0, xmin=min(y_train_pred.min(), y_test_pred.min()), xmax=max(y_train_pred.max(), y_test_pred.max()), color='black', lw=2)
plt.xlim([min(y_train_pred.min(), y_test_pred.min()) - 1, max(y_train_pred.max(), y_test_pred.max()) + 1])
plt.tight_layout()
plt.show()| Linear Regression | RandomForestRegressor | Ridge | DecisionTree |
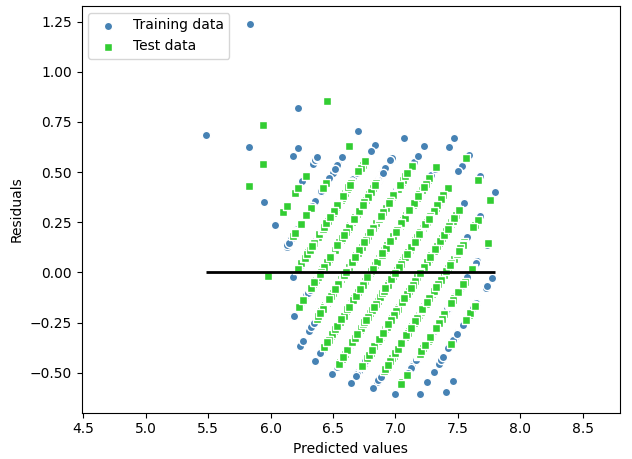 |
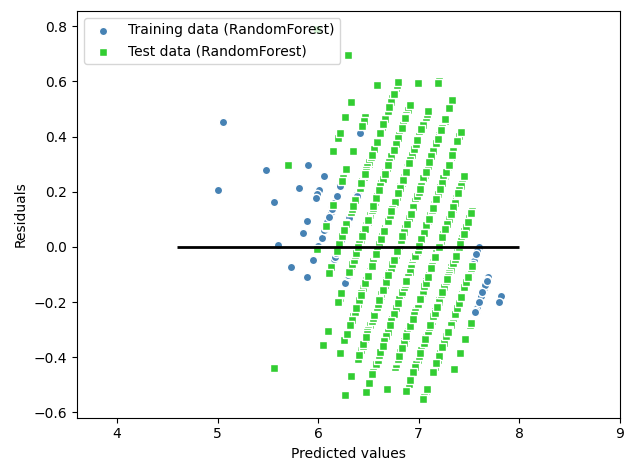 |
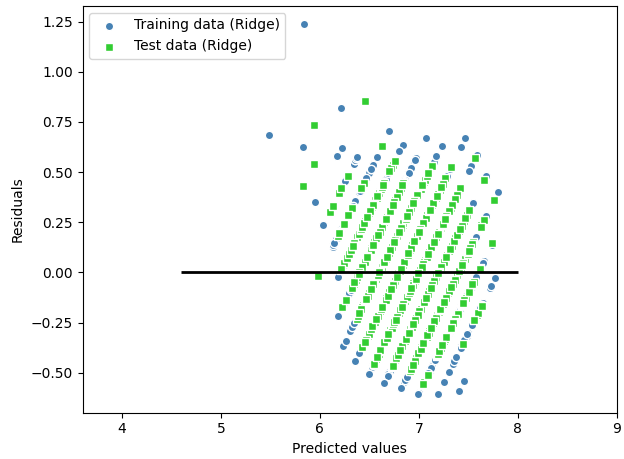 |
 |
 |
 |
 |
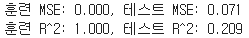 |
※ RandomForestRegressor과 DecisionTree 의 정확도 확인시에 훈련 값에서는 과도하게 높은 값이 나오고 테스트 값에서는 낮은 값이 나오는 과적합 Overfitting 문제 발생!
<파라미터 수정을 통해 DecisionTree 과적합 해결>
데이터를 질문을 통해 나누는 DecisionTree 모델 특성 상 LoL 데이터에서 적합하지 않다고 판단.
질문을 지나치게 많이하면 오버피팅이 생길 수도 있다는 점을 알게 됨
▶ max_depth 파라미터 수정을 통해 오버피팅 해결
tree = DecisionTreeRegressor(max_depth=5, random_state=0)

| max_depth = 3 | max_depth = 5 | max_depth = 7 | max_depth = 10 |
 |
 |
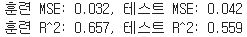 |
 |
max_depth 값이 커질 수록 오버피팅 되는 것을 확인
<파라미터 수정을 통해 RandomForest 과적합 해결>
forest = RandomForestRegressor(n_estimators=1000,
criterion='squared_error',
max_depth=5,
min_samples_split=2,
min_samples_leaf=2,
random_state=1,
n_jobs=--1)


Train과 Test 값 사이의 격차가 줄어듦을 확인
[Decision Tree Regression 그래프 시각화]
X = data[['blueExperienceDiff']].values
y = data['blueAvgLevel'].values
def lin_regplot(X, y, model):
plt.scatter(X, y, c='lightblue')
plt.plot(X, model.predict(X), color='red', linewidth=2)
return
tree = DecisionTreeRegressor(max_depth=5)
tree.fit(X, y)

[각 모델별 결과]
Train: Test=8:2로 나누고 Train Set을 다시 Train: Validation=8:2로 나눔

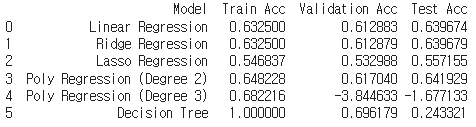
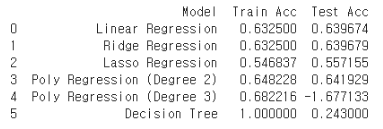
2차 다항회귀에서는 적절하게 예측하지만 3차 다항회귀 모델을 사용했을 때는 과적합 발생을 확인
▷ LoL 데이터를 다루기에 3차 다항회귀 모델은 너무 복잡하여 적합하지 않음.
Decision Tree 모델에서도 과적합 발생을 확인
▷ 파라미터 조정을 하지 않았기에 위에서 작성한 Decison Tree의 과적합 문제와 동일한 이유라고 판단
<실제 연습 + 실습에 사용한 .ipynb 파일>
4. 분류 (Classification)
목적 : 블루팀의 [1] blueWins, 승(1) 패(0) 예측
데이터셋을 Train, Test로 나누었음.
X, y을 7:3 비율로 나눔.
회귀 모델과 동일하게 Red team의 정보를 drop하고 Gold와 관련한 정보는 [12] blueTotalGold 정보만 사용
다만 blueTotalExperience를 Drop 하지 않음
y = 'blueWins'


[RandomForrestRegressor을 이용해 특징 중요도 산출]
from sklearn.ensemble import RandomForestClassifier
feat_labels = data.columns[0:]
feat_labels = feat_labels.drop('blueWins')
print(len(feat_labels))
forest = RandomForestClassifier(n_estimators=500, random_state=1)
print((X_train.shape))
forest.fit(X_train, y_train)
importances=forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(X_train.shape[1]):
print("%2d) %-*s %f"% (f +1, 30,
feat_labels[indices[f]],
importances[indices[f]]))
plt.title('Feature Importance')
plt.bar(range(X_train.shape[1]),
importances[indices],
align='center')
plt.xticks(range(X_train.shape[1]), feat_labels[indices], rotation=90)
plt.xlim([-1,X_train.shape[1]])
plt.tight_layout()
plt.show()

[seaborn을 활용하여 각 열들의 상관관계 확인]
corr = data.corr()["blueWins"].drop(['blueWins'])
corr = corr.sort_values(ascending=False)
sns.barplot(x=corr, y=corr.index)
plt.show()
- 각 열들의 상관관계에서 blueDeaths는 blueWin과 반대로 안 좋은 영향을 주는 역할을 하기에 음수로 표시됨을 확인함
- 특징 중요도와 상관관계 그래프 모두 [16] blueExperienceDiff와 [11] blueTotalGold가 높은 위치에 속하는 것을 확인함
경험치와 Gold 값이 높을 수록 avgLevel 값도 높아짐
▶ 추후 plot_decision_regions를 그릴 때 해당 특징 사용 예정
- 경기 초반의 10분의 내용만을 담고 있기에 상대적으로 Dragon이나 Kill의 수가 경험치나 획득 골드량에 비해 낮은 숫자값을 가지고 있음.
▶ 경험치나 획득 골드량이 상위권을 차지하게 됨. 만약 10분이 아닌 게임 전체의 정보를 가지고 학습하게 된다면 Dragon이나 Kills등의 다른 특징들의 중요도도 올라갈 것이라 예측함.

[Pipeline을 이용해 테스트 정확도 확인]
from sklearn.pipeline import make_pipeline
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
pipe_lr = make_pipeline(StandardScaler(), PCA(n_components=2),
LogisticRegression(random_state=1))
pipe_lr.fit(X_train, y_train)
y_pred = pipe_lr.predict(X_test)
print('테스트 정확도(Logistic):%.3f' % pipe_lr.score(X_test, y_test))
LogisticRegression, SVC, RandomForestClassifier 성능 비교

[K-fold cross-validation]
import numpy as np
from sklearn.model_selection import StratifiedKFold
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=1).split(X_train, y_train)
scores=[]
for k, (train, test) in enumerate(kfold):
pipe_lr.fit(X_train[train], y_train[train])
score = pipe_lr.score(X_train[test], y_train[test])
scores.append(score)
print('Fold: %2d, Classs dist.: %s, Acc: %3f' % (k+1, np.bincount(y_train[train]), score))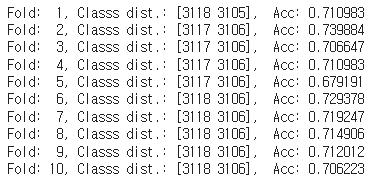
[Plot_decision_regions & Accuracy_score]
<Train Data>
Training Data를 사용해서 Plot_decision_regions를 그려보았음.
Perceptron, DecisionTree, RandomForest, KNeighbors 4가지 모델의 Train accuracy도 함께 확인
+) 처음 Plot_decision_regions 그래프를 그려보았을 때 blueWins과 관련된 특징들은 총 17가지가 존재하는데 어떤 특징들을 사용해서 Plot가 적절하게 그려질지 고민해보았음. 특징 중요도 산출시 가장 높은 중요도를 보였던 상위 2개의 특징을 사용하여 그래프를 그리기로 결정함. [16] blueExperienceDiff와 [11] blueTotalGold
▶ Plot_decision_regions 가 적절하게 나타남!
from sklearn.linear_model import Perceptron
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
# Perceptron
perceptron = Perceptron()
perceptron.fit(X_train[:, [10, 15]], y_train)
# DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='gini', max_depth=4, random_state=1)
tree.fit(X_train[:, [10, 15]], y_train)
# RandomForestClassifier
forest = RandomForestClassifier()
forest.fit(X_train[:, [10, 15]], y_train)
# KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train[:, [10, 15]], y_train)
models = [perceptron, tree, forest, knn]
model_names = ['Perceptron', 'Tree', 'Forest', 'Kneighbors']
plt.figure(figsize=(20, 16))
for i, model in enumerate(models):
plt.subplot(2, 2, i+1)
plot_decision_regions(X_train[:, [10, 15]], y_train, clf=model, legend=2)
plt.xlabel('blueTotalGold')
plt.ylabel('blueExperienceDiff')
plt.title(f'{model_names[i]} Decision Boundary Visualization (Training Data)')
plt.tight_layout()
plt.show()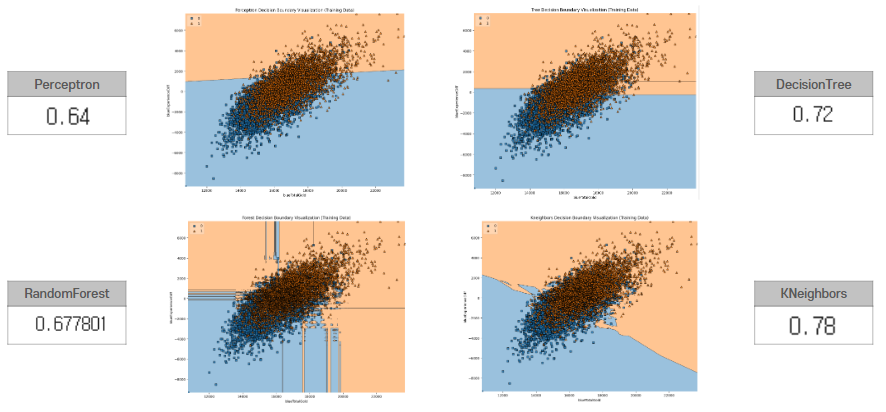
Kneighbors가 가장 높은 정확도를 보임을 확인
<Test Data>
Test Data를 사용해서 Plot_decision_regions를 그려보았음.
Perceptron, DecisionTree, RandomForest, KNeighbors 4가지 모델의 Test accuracy도 함께 확인

Kneighbors가 가장 높은 정확도를 보임을 확인
Plot 하였을 때, 우상단(주황색)에 우승한 경기가 좌하단(파란색)에 패배한 경기가 나타남.
[16] blueExperienceDiff와 [11] blueTotalGold값이 클 수록 주로 우승함.
+ 모델의 정확도를 확인할 때 RandomForest 모델은 Train, Test 정확도가 둘 다 1.0으로 나타나는 과적합 Overfitting 발생!

RandomForest의 각 트리가 너무 깊을 수도 있기에 여러 하이퍼파라미터를 튜닝해서 과적합이 발생하지 않도록 시도함.
n_estimaotrs = 100으로 설정
5-fold cross-validation을 사용해 평균 정확도 출력해봄
max_depth와 n_estimators 를 여러 값으로 변경하여 코드를 돌려본 결과
max_depth는 10, 100, 1000 으로 수정해도 평균 정확도가 달라지지 않음을 확인.
데이터의 특성 상 max_depth가 다른 하이퍼파라미터에 의해 정확도에 미치는 영향이 상쇄될 수 있다는 것을 알게 되었음.
n_estimators를 100, 1000, 10000 으로 수정해본 결과 각 파라미터 값에 따라 평균 정확도가 다르게 나타남을 확인하였음.
n_estimators를 1000으로 돌려본 결과 0.6818, 10000으로 돌려본 결과 0.6791 으로 값을 키울 수록 정확도가 떨어짐.
▶ n_estimators 를 100으로 설정한 값을 사용!
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# 원하는 트리 수로 설정
n_estimators = 100
max_depth = 10
forest = RandomForestClassifier(n_estimators=n_estimators,max_depth=max_depth, random_state=0)
#모델 훈련
forest.fit(X_test[:, [10, 15]], y_test)
# 교차 검증 수행
cv_scores = cross_val_score(forest, X_test[:, [10, 15]], y_test, cv=5)
# 교차 검증 정확도 출력
print("Cross-Validation Scores:", cv_scores)
print("Mean Accuracy:", np.mean(cv_scores))
[각 모델 별 결과]
Gradient Boosting Classifier, Logistic Regression, Random Forest Classifier, SVM, Gaussian Naive Baiyes, KNN, Multi-layer Perceptron 모델로 각 정확도 확인


전체적으로 Logistic Regression 이 높은 정확도를 보임을 확인함
<실제 연습 + 실습에 사용한 .ipynb 파일>
5. 보완할 점
1. 실제로 LOL 게임을 즐겨하는 친구들에게 게임의 승패를 결정하는데 가장 큰 역할을 하는 부분을 물어보았을 때,
'캐릭터를 고르거나 해당 경기에 플레이어들이 특정 캐릭터를 고르지 못하도록 금지하는 과정' 에서 승패가 가장 많이 결정된다는 피드백을 받았음.
(흔히 '밴픽'이라고 불리며 게임 시작 전에 각 팀들은 상대방의 팀이 사용할 수 없도록 캐릭터 5개를 각 팀마다 고름. 이때 선정된 캐릭터는 상대팀이 사용 불가능)
▷ LOL 게임의 특성 상 개인의 게임 실력도 중요하지만, 사용하는 캐릭터의 특징들도 중요한 역할을 함. 추후 각 캐릭터의 조합들을 통해 게임의 승패도 예측해볼 예정임.
2. Blue 팀의 정보를 예측하기 위해 Red team의 정보는 Drop 시켜 학습을 진행하였는데, Red team의 정보들을 함께 사용하여 예측 모델을 제작해볼 수 있음.
3. 현재 10분 동안 진행되는 게임의 정보를 가지고 있지만 게임의 후반부가 되면 경험치나 Gold의 양 말고 다른 특징에서도 높은 중요도를 나타낼 수 있다고 생각함. 게임이 진행된 전체 정보를 가지고 모델을 만들어보고 싶음.
'AI' 카테고리의 다른 글
| [OpenCV 오류] module 'cv2' has no attribute 'createThinPlateSplineShapeTransformer' (0) | 2024.01.30 |
|---|---|
| [실전! 컴퓨터비전을 위한 머신러닝] 2. 컴퓨터비전에 쓰이는 ML 모델 (0) | 2023.09.12 |
| Yolov5, Yolov8 공부 (1) | 2023.05.30 |
| Faster R-CNN (0) | 2023.05.30 |
| Teachable Machine을 사용한 쓰러짐 감지 AI 구현 (0) | 2023.01.05 |


