가중치 매개변수의 최적값을 탐색하는 최적화 방법, 가중치 매개변수 초깃값, 하이퍼파라미터 설정 방법
6.1 매개변수 갱신
최적화 - 매개변수의 최적값을 찾는 문제를 푸는 것
<확률적 경사 하강법 (SGD) >
기울어진 방향으로 매개변수의 값을 반복해서 갱신해 최적의 값에 다가감

class SGD:
def __init__(self, lr=0.01):
self.lr=lr
def update(self, params, grads):
for key in params.keys():
params[key]-= self.lr*grads[key]optimizer=SGD()
optimizer.update(params, grads)Optimizer에 매개변수와 기울기 정보를 넘겨줌
<단점>

비등방성 함수에서 탐색 경로가 비효율적 (지그재그로 이동)
→ 단점 개선) 모멘텀, AdaGrad, Adam
<모멘텀>

W - 갱신할 가중치 매개변수
aL/aW - W에 대한 손실 함수의 기울기
n - 학습률
v - 속도
av - 물체가 아무런 힘을 받지 않을 때 서서히 하강시킴
공이 그릇의 바닥을 구르는 듯한 움직임
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr=lr
self.momentum = momentum
self.v=None
def update(self, params, grads):
if self.v is None:
self.v={}
for key, val in params.items():
self.v[key]=np.zeros_like(val)
for key in params.keys():
self.v[key]=self.momentum*self.v[key]-self.lr*grads[key]
params[key]+=self.v[key]
x축의 힘은 아주 작지만 방향이 변하지 않아서 한 방향으로 일정하게 가속함.
y축의 힘은 크지만 위아래로 번갈아 받아 상충하여 속도는 안정적이지 않음
+) 바이킹 탄다고 생각하기. 0으로 가까워질 때 점 사이의 거리는 넓어짐. 속도가 일정하지 않음
<AdaGrad>
학습률 값이 너무 작으면 학습 시간이 길어짐. 너무 크면 발산하여 학습이 제대로 이뤄지지 않음
→ 학습률 정하는 방법) 학습률 감소
학습을 진행하면서 학습률을 점차 줄여감 (처음엔 크게 학습 후 조금씩 작게)
매개 변수 '전체'의 학습률 값을 일괄적으로 낮춤 → '각각의' 매개변수에 '맞춤형' 값을 만들어줌
개별 매개변수에 적응적으로 학습률을 조정하며 학습 진행

h - 기존 기울기 값을 제곱하여 계속 더해줌
학습률 감소가 매개변수 원소마다 다르게 적용됨
+) RMSProp - 먼 과거의 기울기는 서서히 잊고 새로운 기울기 정보를 크게 반영
지수이동평균 - 과거 기울기의 반영 규모를 기하급수적으로 감소시킴
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-71e-7 = 작은 값을 더해 0으로 나누는 사태를 막음

y축 방향은 크기가 커서 처음에는 크게 움직임. 큰 움직임에 비례해 갱신 정도도 큰 폭으로 작아짐
y축 방향 갱신강도가 빠르게 약해짐. 지그재그 움직임이 줄어듦
<Adam>
모멘텀 + Adagrad
하이퍼파라미터의 '편향 보정'이 진행됨
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None학습률, 일차 모멘텀용 계수, 이차 모멘텀용 계수 (하이퍼파라미터 3개)

일 반적으로 SGD의 학습 진도가 가장 느리고 나머지 세 기법이 빠르게 학습함 (때로는 최종 정확도도 높게 나타남)
6.2 가중치의 초깃값
<가중치 감소>
오버피팅을 억제해 범용 성능을 높임. 가중치 매개변수의 값이 작아지도록 학습하는 방법
▶ 가중치 초깃값을 0으로 학습하면 안됨 (균일한 값) → 오차역전파법에서 모든 가중치의 값이 똑같이 갱신됨.
def sigmoid(x):
return 1/(1+np.exp(-x))
x=np.random.randn(1000, 100) #1000개의 데이터
node_num=100 #각 은닉층의 노드(뉴런) 수
hidden_layer_size=5 #은닉층이 5개
activations={} #이곳에 활성화 결과(활성화값)를 저장
for i in range(hidden_layer_size):
if i!= 0:
x=activations[i-1]
w=np.random.randn(node_num, node_num*1)
a=np.dot(x,w)
z=sigmoid(a)
activations[i]=z<가중치를 표준편차가 1인 정규분포로 초기화할 때의 각 층의 활성화 값 분포>

각 층의 활성화 값들이 0과 1에 치우져 있음.
기울기 소실 발생
<가중치를 표준편차가 0.01인 정규분포로 초기화할 때의 각 층의 활성화 값 분포>

각 층의 활성화 값들이 0.5 부근에 집중되어 있음.
다수의 뉴런이 거의 같은 값을 출력 → 뉴런을 여러개 둔 의미가 없음
표현력이 제한됨.
<Xavier 초깃값>

앞 층에 노드가 많을수록 대상 노드의 초깃값으로 설정하는 가중치가 좁게 퍼짐
node_num = 100
w = np.random.randn(node_num, node_num) / np.sqrt(node_num)
<He 초깃값>
ReLu에 특화된 초깃값 - 루트 2/n

std = 0.01 일때 각 층의 활성화값들은 아주 작은 값 = 역전파 때 가중치의 기울기 역시 작아짐
Xavier = 층이 깊어지면서 치우침이 조금씩 커짐. 학습할 때 '기울기 소실' 문제를 일으킴 (sigmoid, anh 등의 S자 모양 곡선)
He = 모든 층에서 균일하게 분포. (ReLu)
6.3 배치 정규화
1. 학습을 빨리 진행할 수 있음
2. 초깃값에 크게 의존하지 않음
3. 오버피팅을 억제함

미니배치 단위를 정규화함 (데이터 분포 평균이 0, 분산이 1)

활성화 함수의 앞에 삽입함으로써 데이터 분포가 덜 치우치게 함.
정규화된 데이터에 고유한 확대와 이동 변환을 수행함

r =1, b=0 부터 시작함.
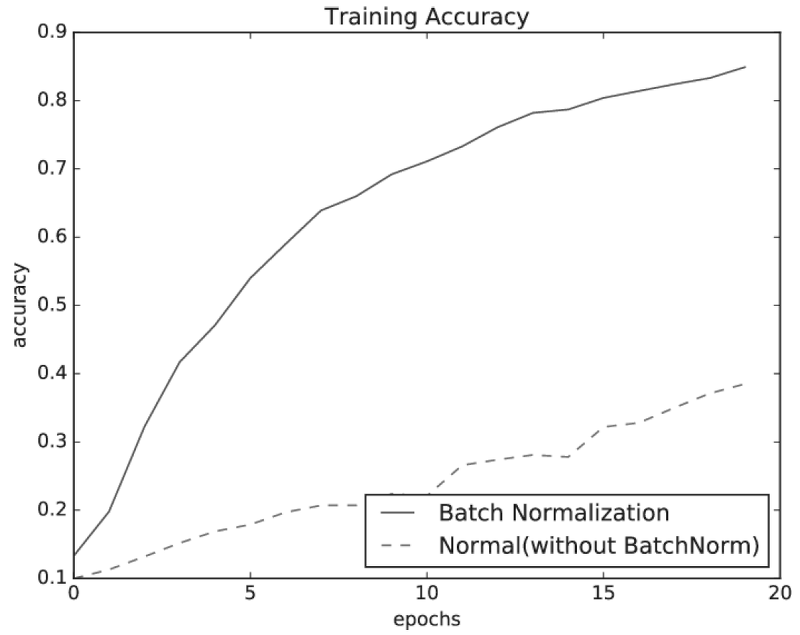
배치 정규화를 사용할 때 학습 진도가 빠름
6.4 바른 학습을 위해
<오버피팅>
- 매개변수가 많고 표현력이 높은 모델
- 훈련 데이터가 적음

100에폭을 지나는 무렵부터 거의 100%
정확도가 크게 벌어지는 것 - 훈련 데이터에만 적응해버린 결과
<가중치 감소>
큰 가중치에 대해서 그에 상응하는 큰 페널티를 부과하여 오버피팅을 억제함
가중치의 제곱 노름을 손실 함수에 더함

훈련 데이터에 대한 정확도가 100%에 도달하지 못함
<드롭아웃>
은닉층의 뉴런을 무작위로 골라 삭제함
훈련 때 데이터를 흘릴 때마다 삭제할 뉴런을 무작위로 선택. 시험 때 뉴런의 출력에 훈련 때 삭제 안 한 비율을 곱해서 출력
시험 때 모든 뉴런에 신호를 전달함
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask=None
def forward(self, x, train_flg=True):
if train_flg:
self.mask=np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x*(1.0-self.dropout_ratio)
def backward(self, dout):
return dout*self.mask훈련시에는 순전파 때마다 self.mask 에 삭제할 뉴런을 False로 표시함
# 오버피팅을 재현하기 위해 학습 데이터 수를 줄임
x_train = x_train[:300]
t_train = t_train[:300]
# 드롭아웃 사용 유무와 비울 설정 ========================
use_dropout = True # 드롭아웃을 쓰지 않을 때는 False
dropout_ratio = 0.2
+ 앙상블 학습 - 개별적으로 학습시킨 여러 모델의 출력을 평균내어 추론하는 방식
(추론할 때는 뉴런의 출력에 삭제한 비율을 곱함으로써 앙상블 학습에서 여러 모델의 평균을 내는 것과 같은 효과)
6.5 적절한 하이퍼파라미터 값 찾기
훈련 데이터 - 학습, 시험 데이터 - 범용 성능 평가
하이퍼파라미터의 성능 평가할 때 시험 데이터 사용 X
→ 시험 데이터를 사용하여 하이퍼파라미터를 조정하면 하이퍼파라미터 값이 시험 데이터에 오퍼피팅 됨
시험 데이터에만 적합하도록 조정됨.
검증 데이터 - 하이퍼파라미터 전용 확인 데이터
<하이퍼파라미터 최적화>
- '최적 값'이 존재하는 범위를 조금씩 줄여나감.
- 대략적인 범위 설정 후 범위에서 무작위로 샘플링, 그 값으로 정확도 평가
- 로그 스케일로 지정함
0단계
하이퍼파라미터 값 범위 설정
1단계
설정된 범위에서 하이퍼파라미터 값 무작위로 추출
2단계
샘플링한 하이퍼파라미터 값 사용해서 학습, 검증 데이터로 정확도 평가 (에폭은 작게)
3단계
1단계와 2단계를 특정횟수 반복, 정확도 결과보고 하이퍼파라미터의 범위를 좁힘

잘될 것 같은 값의 범위를 관찰하고 범위를 좁혀나감. 축소된 범위로 똑같은 작업 반복
특정 단계에서 최종 하이퍼파라미터 값을 하나 선택
'AI > 딥러닝' 카테고리의 다른 글
| [밑바닥부터 시작하는 딥러닝] 8장 딥러닝 (0) | 2023.04.29 |
|---|---|
| [밑바닥부터 시작하는 딥러닝] 7장 합성곱 신경망(CNN) (0) | 2023.04.15 |
| [밑바닥부터 시작하는 딥러닝] 5장 오차역전파법 (0) | 2023.04.01 |
| [밑바닥부터 시작하는 딥러닝] 4장 신경망 학습 (0) | 2023.03.25 |
| [밑바닥부터 시작하는 딥러닝] 3장 신경망 (0) | 2023.03.18 |



