Face super-resolution - 저해상도(LR) 이미지에서 고해상도 (HR) 얼굴 이미지를 재구성하는 문제
scale factor - HR 이미지와 LR 이미지 사이의 해상도 비율
실제 값(GT) - ground truth.
"Scale factors"는 이미지의 해상도나 크기를 조절하는 비율
GANs에 의해 학습된 얼굴 세부 정보를 활용하여 고품질 이미지를 생성
▶ 가짜 세부 정보를 재구성하고 원래 얼굴을 심각하게 변경하여 신원 손실을 초래할 수 있음
[GAN]
GAN은 기본적으로 생성자(Generator)와 판별자(Discriminator)라고 불리는 두 개의 신경망이 경쟁하는 구도임
StyleGAN
생성적 적대 신경망(GAN) 기반의 이미지 생성 모델
이미지를 여러 style들의 조합으로 보기 때문에 각각의 layer를 거쳐가며 style 정보를 입히는 방식으로 이미지를 합성
참조 이미지 예시 - 개인 앨범에서 추출한 고해상도 얼굴 사진, 전문적인 사진 스튜디오에서 촬영한 얼굴 이미지, 또는 다른 출처에서 가져온 높은 품질의 얼굴 이미지
참조 정보를 얼굴 초해상화에 직접적으로 사용하는 것은 간단하지 않음 - 악세서리 같은 비얼굴 영역 때문에
참조 기반 얼굴 초해상화(RPF) 알고리즘
비얼굴 영역 제거를 기반으로 마스킹하여 비얼굴 영역의 변동성으로 인한 부정적인 영향을 방지
reference-based progressive face SR (RPF) network 제안
- 재구성 블록( reconstruction blocks) 을 반복적으로 사용하여 입력 해상도를 점진적으로 확대
각 재구성 블록에는 왜곡, 합성 및 정제를 위한 세 가지 모듈이 포함
- 왜곡 모듈은 마스킹된 HR 참조와 LR 입력 간의 모션 필드를 추정하여 참조를 입력에 맞춥니다.
- 합성 모듈은 참조 정보를 사용하여 세밀하고 충실하게 얼굴 세부 정보를 재구성합니다.
- 정제 모듈은 비얼굴 영역에 대한 타당한 세부 정보를 생성하며 얼굴 영역을 미세 조정하여 얼굴 세부 정보를 더 향상시킵니다
StyleGANs [8], [9]과 같은 생성 모델은 자세하고 현실적인 얼굴 이미지를 무작위로 생성할 수 있지만, 사용자가 원하는 이미지를 생성하기는 어렵
세부 정보는 입력 이미지에서 보간된 것이 아닌 가짜 세부 정보일 수 있음
x의 공간 해상도 = L × L
LR 이미지 x, HR 이미지 y, y와 다르지만 동일한 사람의 얼굴을 포함하는 참조 이미지 r
참조 r의 정보를 활용하여 LR 이미지 x로부터 HR 이미지 y를 복원하는 것이 목표
여러 재구성 블록을 통해 rˆ을 사용하여 x를 점진적으로 확대
3p ". Therefore, rather than being helpful for SR, non-facial regions often cause visual artifacts in SR."
비얼굴 영역이 SR의 목표인 얼굴 세부 정보 복원을 방해하거나 왜곡시킬 수 있음.
"mask value" - 비얼굴 영역과 얼굴 영역을 나타내는 이진 마스크에서 각 픽셀에 할당된 값
마스크 값이 1이면 해당 픽셀의 값을 유지하고, 0이면 해당 픽셀의 값을 0으로 만듦.
알고리즘
참조 이미지 r을 비얼굴 영역/얼굴 영역으로 나눔. - 2의 거듭제곱으로 다운 샘플링
저해상도 LR이미지 x를 다운샘플링한 참조 이미지 r과 함께 재구성 블록에 입력으로 제공됨.
▶ 더 높은 해상도의 출력 이미지가 생성
1. WARPING MODULE (왜곡 모듈)
먼저 의 해상도를 컨볼루션 레이어와 픽셀 셔플 레이어를 사용하여 두 배로 증가시킴. 그런 다음 입력과 참조 정보를 연결하고 옵티컬 플로우 추정을 수행
다운스케일 블록으로 구성된 인코더와 업스케일 블록으로 구성된 디코더를 포함
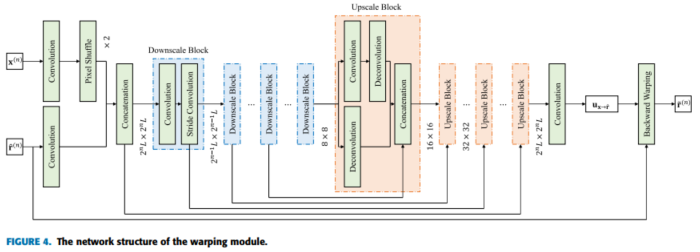
backward warping operator - 이미지 워핑에서 사용되는 연산자 중 하나
: 목적지 이미지의 각 픽셀을 소스 이미지로 역방향으로 매핑하는 방법입니다. 역방향으로 목적지에서 소스로의 픽셀 값 찾기를 수행합니다.
2. SYNTHESIS MODULE (합성 모듈)
의 해상도를 두 배로 증가시키기 위해 컨볼루션 레이어와 픽셀 셔플 레이어를 사용하고, 을 다른 컨볼루션 레이어를 통과시킴
이를 연결하고, 고주파 정보를 입력으로 전송하기 위해 네 개의 잔여 블록을 사용하여 최종적으로 합성된 이미지 x을 얻음.
3. REFINEMENT MODULE (정제 모듈)
비얼굴 영역에 신뢰성 있는 세부 정보를 생성하기 위해 세분화 모듈을 설계
인코더-디코더 아키텍처
인코더 : 두 개의 스트라이드 컨볼루션 레이어와 K개의 완전 연결 (FC) 레이어를 포함하는 임베딩 블록
디코더 : K개의 업스케일 블록

바이큐빅 보간(Bicubic interpolation)
- 16개의 가장 가까운 인접 픽셀의 가중 평균을 취하여 각 새 픽셀의 값을 추정하는 방법
n번째 재구성 블록을 훈련하기 위한 손실
1. 워핑손실 - HR 참조 이미지 r을 GT y에 워핑하여 워핑된 참조 rwarp
2. 합성손실 - 참조 이미지의 비얼굴 영역이 부정적인 영향을 미치지 않도록 얼굴 영역에만 초점을 맞춤, 얼굴 영역에서의 합성 오류에 패널티를 부과
3. 리파인먼트 손실 - Lref는 재구성 손실 Lrec(r), 지각 손실 Lper, 신원 손실 Lid 및 적대적 손실 Ladv(r)의 조합으로 정의
재구성된 이미지에서 정체성 정보의 보존에 중점
[평가지표]
- PSNR (피크 신호 대 잡음 비):
- 이미지 재구성의 품질을 측정.
- 높은 값은 높은 이미지 품질을 나타냄.
- SSIM (구조 유사성 지수 측정):
- 두 이미지 간의 구조적 유사성을 평가.
- 값은 -1에서 1까지이며, 1은 동일한 이미지를 나타냄.
- LPIPS (학습된 지각적 이미지 패치 유사성):
- 이미지 간의 지각적 유사성을 측정.
- 낮은 값은 높은 유사성을 나타냄.
- ISC (정체성 유사성 점수):
- 초해상된 이미지에서 정체성 정보의 보존을 측정.
- 높은 값은 높은 정체성 보존을 나타냄.
[8] T. Karras, S. Laine, and T. Aila, ‘‘A style-based generator architecture for generative adversarial networks,’’ in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 4401–4410.
Style-based generator를 사용한 GAN구조를 StyleGAN
[PGGAN]
baseline으로 사용된 PGGAN을 간단하게 설명하면 학습과정에서 layer를 추가하는 방식의 고해상도 이미지 생성에 잘 동작하는 GAN model
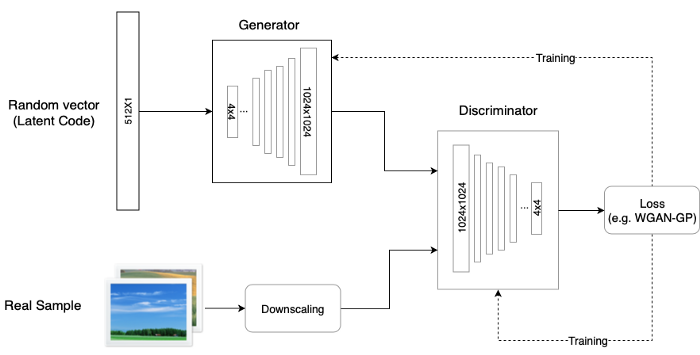
진적으로 layer를 추가하면서 학습하기 때문에 안정적으로 high resolution image를 만듦
- 1. Mapping Network
- 2. Synthesis Network



