객체 검출
이미지에서 위치 정보를 제공하는 과업
YOLO
YOLO 격자
그림은 N x M 칸으로 분할
셀 내부 어딘가에 중심점을 갖는 객체에 대한 경계 박스를 예측함
객체 검출 헤드
숫자 6개 예측
- 경계 박스의 좌표 4개, 객체가 검출됐는지를 나타내는 확신도, 객체의 클래스
너비와 높이는 [0,1] 범위에 속하도록 시그모이드 활성화 사용
확신도 C도 [0,1] 범위에 있으므로 소프트맥스 활성화 사용
Q. 올바른 차원의 특징 맵을 얻는 방법에는?
A. 컨볼루션 백본에서 반환되는 특징 맵을 모두 평탄화해서 출력 개수와 같은 수의 완전 연결 레이어에 먹이는 것
손실 함수
훈련 데이터 내에 정답 - 실측 박스 (ground truth box)
예측 박스 (predicted box)
실측 박스와 결자 셀 내의 모든 예측 박스 간의 IOU 를 계산, IOU가 가장 높은 쌍을 선택

손실
객체 존재 손실, 객체 부재 손실, 객체 분류 손실, 경계 박스 손실
YOLO의 한계
1.격자 셀당 단일 클래스를 예측하고 동일한 셀에 다른 종류의 여러 객체가 있으면 제대로 작동하지 않음
2. 격자 자체.
- 고정 격자 해상도로 인해 공간적 제약이 따름. 데이터셋에 맞춰 격자를 조정하지 않으면 작은 객체들이 모여 있는 것에서는 잘 작동하지 않음 (ex. 철새)
3. 객체를 지역화하는 정밀도가 떨어지는 편임
레티나넷
경계박스 표현을 변경하는 앵커박스에서 시작하는 박스를 예측함
현재 단일 샷 검출기 중에서는 최고로 뽑힘
FPN
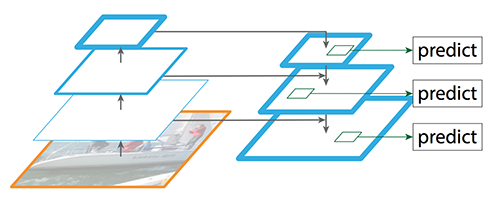
YOLO 아키텍처에서 마지막 특징 맵만을 검출에 사용
▶객체를 정확하게 식별 O, 지역화 정확도는 제한!
Q. 모든 규모에서 좋은 공간 정보와 좋은 의미 정보를 모두 표시하는 방식으로 모든 특징 맵을 결합하는 방법은?
A. 특징 피라미드망(FPN)을 형성하는 레이어를 몇 개 추가함.
컨볼루션 레이어는 특징 맵의 의미 정보를 점차 다듬어감.
풀링 레이어는 공간 차원에서 특징 맵을 축소함.
- 좋은 상위 수준 정보가 있는 아래쪽 레이어의 특징 맵은 스택의 상위 특징 맵에 요소 별로 추가될 수 있게 업샘플링됨
- FPN 레이어에는 비선형성이 없음
- FPN 설계는 하부 컨볼루션 백본에 독립적이라는 점에서 뛰어남
- 사전 훈련된(ex. 레즈넷, 이피션트넷) 백본을 사용할 수도 있음.
- 특징을 추출하여 FPN에 먹일 수 있는 여러 수준이 있음.
- 추가 풀링 및 컨볼루션 레이어를 사용해 기존의 사전 훈련된 백본을 확장하는 것도 가능함
앵커 박스
검출 박스는 기본 박스 세트에 대한 델타 Δ 로 계산 - 이미지에 겹쳐진 단순한 격자
다양한 종횡비와 스케일의 앵커박스를 명시적으로 정의

레티나넷 9가지 앵커 유형
세 가지 종횡비: 2:1, 1:1, 1:2
세 가지 크기: 1, 1.3, 1.6
<연산 순서>
입력 이미지를 5개의 특징 맵으로 축소함
특징 맵은 이미지 전체에 걸쳐 일정한 간격의 위치에 있는 앵커와 관련된 경계 박스를 예측하는데 사용
(ex. 256개의 채널이 있는 이미지)
검출 헤드는 다중 컨볼루션 레이어를 사용해 256 채널의 특징맵을 정확히 9*4=36 채널로 변환해 위치당 9개의 검출 박스를 만들어냄.
FPN의 각 특징 맵은 앵커 박스의 다른 스케일을 사용
<파라미터>
특징 피라미드에는 P3,P4,P5,P6,P7 스케일
특징 피라미드 수준별 앵커 베이스 크기는 각각 32X32, 64X64, 128X128, 256X256, 512X512 픽셀임
각 특징 피라미드 수준에서 입력 이미지에 걸쳐 박스가 각각 8,16,32,64,128 픽셀 간격으로 배치됨
검출 손실 계산
쌍별로 IOU를 계산해서 N행, M 행의 행렬로 배열함
아키텍처
공간 차원
특징맵은 3차원. 그 중 두차원의 x와 y 차원. 세번째 차원은 채널 수
<파라미터 예측>
(모든 공간 위치에 대해. 이 경우 B=9)
클래스 예측 헤드는 모든 앵커 유형에 대한 하나의 확률 집합인 B*K 확률을 예측 (모든 앵커에 대해 단일 클래스 예측)
검출 헤드는 B*4=36 개의 박스 델타 x,y,w,h를 예측
분류 헤드는 모든 앵커에 대해 K 개의 이진 분류를 예측하도록 설계
= 시그모이드 활성화로 끝남
초점손실(분류)
위치당 9개의 앵커박스가 있는 경우 십만개의 예측 박스가 만들어짐
검출 모델에서는 배경 박스에 대당하는 손실이 전체 손실에서 유용한 탐지에 해당하는 손실을 압도할 수 있음.
▷ 초점 손실
손실 함수를 조정하여 빈 배경에서 훨씬 더 작은 값 생성
앵커 박스 십만개 모두의 손실을 추가해서 전체 손실이 압도되는 것을 걱정X
부드러운 L1 손실(박스 회귀)
L1 (절대 손실) - 경사가 모든 곳에서 같음
L2 (제곱 손실) - 예측값과 목푯값의 차이를 제곱하므로, 예측값과 목푯값이 멀어질 수록 손실이 매우 커짐
▷ 후버 손실 (부드러운 L1 손실)
작은 값에 대해서는 L2 손실처럼 작용하고 큰 값에 대해서는 L1 손실처럼 작용함
비최대 억제(NMS)
박스 중첩(IOU)와 클래스 확신도를 고려해 객체를 가장 잘 나타내는 박스를 선택
두 박스가 겹친 정도가 A 값보다 크면 더 높은 클래스 확신도를 갖는 박스를 살림
- 비슷한 장소에 나비가 두 마리 있으면 한마리가 폐기됨
소프트 NMS
최대가 아닌 겹치는 박스를 모두 제거하되, exp인자에 따라 확신도 점수를 낮춤.
최대 박스에 대해 가장 높은 확신도 점수를 가진 박스를 고려하고, 이 인자만큼 다른 모든 박스에 대한 점수를 줄임
- 비슷한 장소에 있는 나비 중 한 마리의 확신도가 낮아지기는 하지만 두마리 모두 검출 가능
+ 필요한 데이터 양을 줄이기 위해 사전 훈련된 백본이 일반적으로 쓰임
세분화
인스턴스 세분화
검출된 모든 객체에 대해 각 객체의 모양을 제공하는 픽셀 마스크를 추가함
의미 세분화
특정 인스턴슬르 검출하지는 않되, 이미지의 모든 픽셀을 각각의 범주로 분류함
마스크 R-CNN 과 인스턴스 세분화
영역제안망(RPN)
첫 번째 신경망이 객체가 대략 어디쯤 있다고 제안하면 두 번째 망이 제안 위치를 분류하고 정확한 위치를 구함)
객체 & 배경 두 가지 클래스에만 집중된 단순화 된 단일 샷 검출망
객체 - 데이터셋에서 라벨링 된 것
배경 - 객체를 포함하지 않는 박스
컨볼루션 백본, FPN 앵커 박스 세트 및 2개의 헤드
수정된 훈련 데이터셋에서 계산된 자체 손실 함수 O
모든 실측 객체의 클래스는 단일 클래스 '객체'로 대체됨
R-CNN
관심 영역으로 오려낸 이미지를 객체를 분류하기 위해 분류 헤드가 붙은 백본에 다시 한 번 통과시킴

전치된 컨볼루션
학습된 업샘플링 연산을 수행
원본 이미지에 (ex. 3x3) 필터를 곱하고 그 결과가 출력됨.
보폭 2의 전치된 컨볼루션에서 출력 창은 모든 입력 픽셀에 대해 2단계 씩 이동해 더 큰 이미지 생성
인스턴스 세분화
관심 영역마다 더 많은 작업을 더 높은 정밀도로 수행!
관심 영역에 대한 특징 맵의 리샘플링 및 정렬을 실제로 두 번 수행
U-NET과 의미론적 세분화
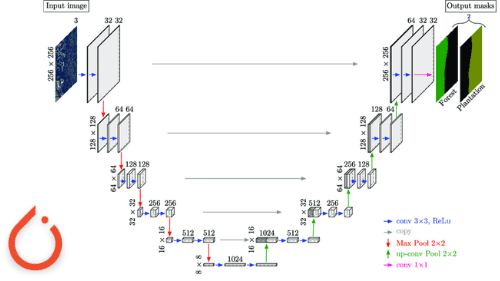
이미지를 인코딩으로 다운샘풀링하는 인코더
인코딩을 다시 원하는 마스크로 업샘플링 하는 반전 디코더
<이미지와 라벨>
라벨 - 배경, 객체 윤곽선, 객체 내부
model = unet_model(OUTPUT_CHANNELS)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])세 가지 픽셀값을 클래스 라벨의 인덱스로 취급
사전 훈련된 모바일 넷 V2 사용
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
인코더의 특정한 레이어로부터의 특징맵을 이름으로 얻어옴
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
'다운 스택'
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs,
name='pretrained_mobilenet')
down_stack.trainable = False
'업샘플링'
def upsample(filters, size, name):
return tf.keras.Sequential([
tf.keras.layers.Conv2DTranspose(filters, size, strides=2, padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.ReLU()
], name=name)
up_stack = [
upsample(512, 3, 'upsample_4x4_to_8x8'),
upsample(256, 3, 'upsample_8x8_to_16x16'),
upsample(128, 3, 'upsample_16x16_to_32x32'),
upsample(64, 3, 'upsample_32x32_to_64x64')
]
디코더 상위 스택의 각 단계를 인코더 하위 스택의 해당 레이어와 이어 붙이고 케라스 콜백을 사용해 예측 표시
for idx, (up, skip) in enumerate(zip(up_stack, skips)):
x = up(x)
concat = tf.keras.layers.Concatenate(name='expand_{}'.format(idx))
x = concat([x, skip])
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
if epoch%5 == 0:
# clear_output(wait=True) # if you want replace the images each time, uncomment this
show_predictions(train.batch(1), 1)
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))'AI > Computer Vision' 카테고리의 다른 글
| [Vision Transformer(ViT)] 코드 설명 및 인자 정리 (0) | 2024.09.23 |
|---|---|
| [Active Learning] 데이터 Pre-training, 학습 진행 (0) | 2024.05.27 |
| [실전! 컴퓨터 비전을 위한 머신러닝] 06. 전처리 (1) | 2023.10.28 |
| [실전! 컴퓨터 비전을 위한 머신러닝] 03. 이미지 비전 (2) (0) | 2023.10.01 |
| [실전! 컴퓨터 비전을 위한 머신러닝] 03. 이미지 비전 (0) | 2023.09.20 |



