[Vit 를 사용한 코드 구현 중 인자 정리 및 개념 정리]
참고 코드 : https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit.py
vit-pytorch/vit_pytorch/vit.py at main · lucidrains/vit-pytorch
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch - lucidrains/vit-pytorch
github.com
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout),
FeedForward(dim, mlp_dim, dropout = dropout)
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return self.norm(x)
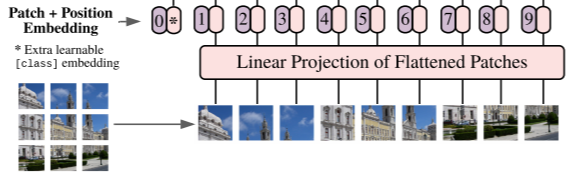
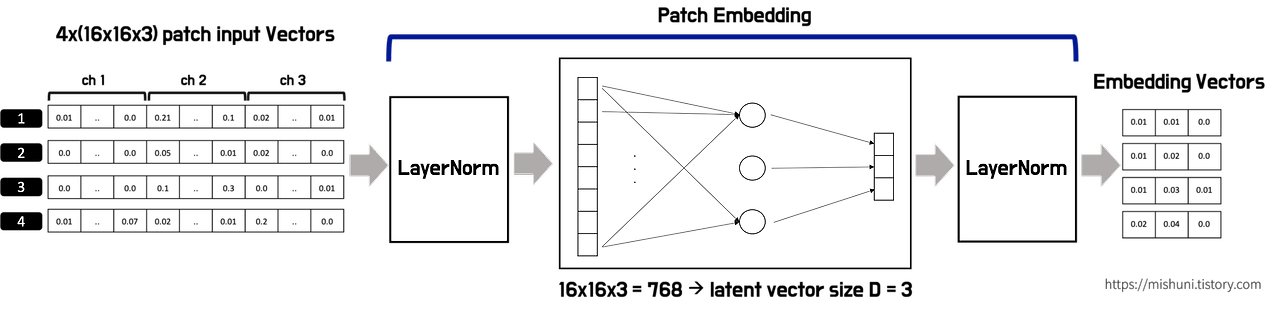
Dim 인자
: Vit는 이미지를 패치 임배딩 후 linear로 선형화 진행함
이때 몇차원으로 선형화를 진행할 것인지를 결정하는 인자
ex. dim 768 → [1,64,768] / dim 1024 → [1,64,1024]
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
Depth 인자
: Transformer 모델에서 레이어의 깊이를 결정하는 데 사용
for _ in range(depth):
self.layers.append(nn.ModuleList([
Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout),
FeedForward(dim, mlp_dim, dropout = dropout)
]))
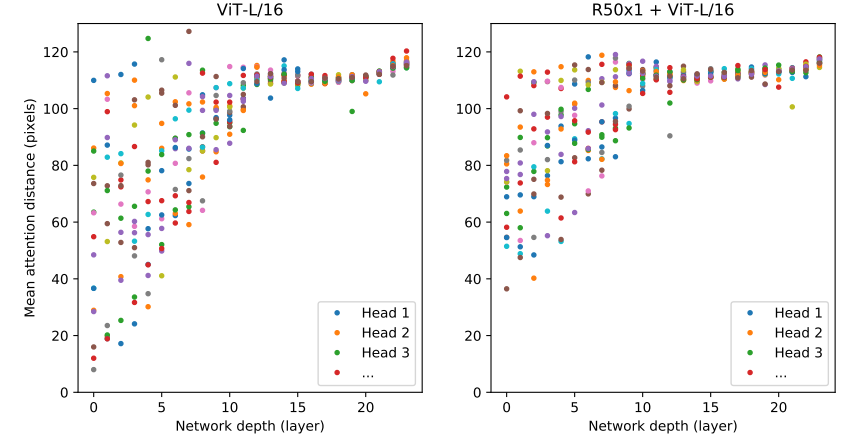
+ Vit 논문 Figure 11
: Depth 깊이가 깊을 수록 성능 향상됨을 보임, 16개의 레이어 이후로는 성능 향상이 점차 줄어드는 것을 볼 수 있음
ViT의 attention 거리는 CNN의 수용 영역 크기와 비슷한 개념, 깊이가 증가함에 따라 모든 헤드에서 attention 거리가 증가
<Vit 코드 저자의 인자 설정 : https://github.com/lucidrains/vit-pytorch/blob/main/vit_pytorch/vit_1d.py >
if __name__ == '__main__':
v = ViT(
seq_len = 256,
patch_size = 16,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 8,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
mlp_dim 인자
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)↓
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout),
FeedForward(dim, mlp_dim, dropout = dropout)
]))↓
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
최종적으로 FeedForward에서 hidden_dim의 역할을 함
: 중간 계층의 차원을 정의
작동되는 방식은 첫번째 Dim 인자의 설명과 동일함
<Multi - Head Attention 설명>
참고 : https://187cm.tistory.com/85
논문 톺아보기 및 코드 구현 [ViT-1] - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ICLR
필자가 이 논문을 처음 봤을 때가 2022.11.14일인데, 이 때 기준 인용 수가 8829이다. 현재 2023.09.22기준 21446회.. 그 당시에도 한달마다 몇백회씩 인용수가 늘어나는 것이 놀라웠는데, 이젠 그 이상으
187cm.tistory.com
dim_head 인자
- Multi Head Attention에서 각 Head의 차원을 정의함
x = [1,4,192] 로 입력되고, Head의 갯수가 4라면, dim_head의 값은 192 / 4 = 48이 되어야함.
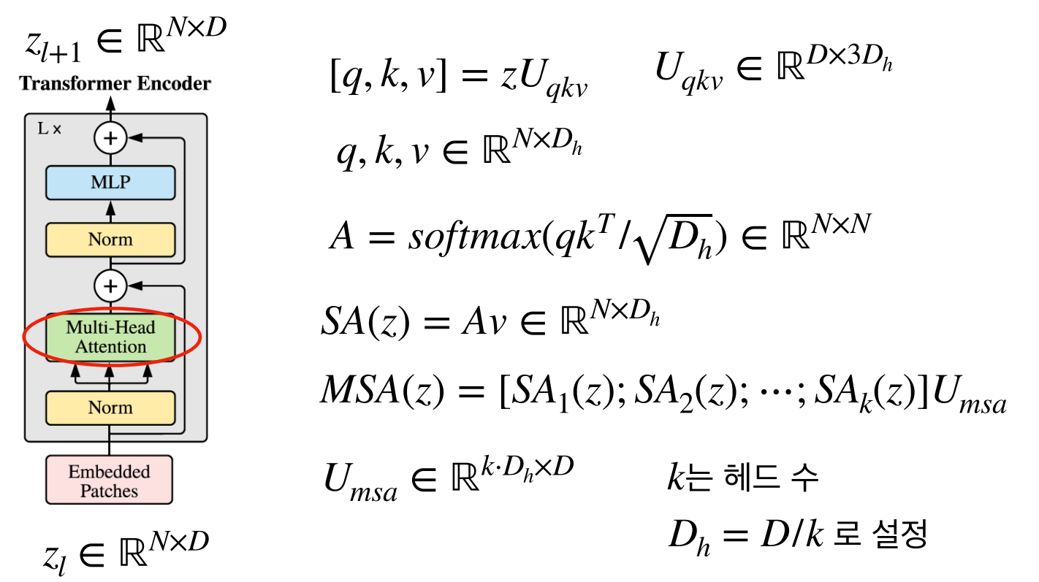
'AI > Computer Vision' 카테고리의 다른 글
| [Yolov10] Custom Data 실습 코드 (1) | 2024.11.18 |
|---|---|
| [Active Learning] 데이터 Pre-training, 학습 진행 (0) | 2024.05.27 |
| [실전! 컴퓨터 비전을 위한 머신러닝] 06. 전처리 (1) | 2023.10.28 |
| [실전! 컴퓨터 비전을 위한 머신러닝] 04 객체 검출과 이미지 세분화 (1) | 2023.10.08 |
| [실전! 컴퓨터 비전을 위한 머신러닝] 03. 이미지 비전 (2) (0) | 2023.10.01 |



